Generating 3D visual scenes is at the forefront of visual generative AI, but current 3D generation techniques struggle with generating scenes with multiple high-resolution objects. Here we introduce Lay-A-Scene, which solves a task of Open-set 3D Object Arrangement, effectively arranging unseen objects. Given a set of 3D objects, the task is to find a plausible arrangement of these objects in a scene. We address this task by leveraging pre-trained text-to-image models. We personalize the model and explain how to generate images of a scene that contains multiple predefined objects without neglect. Then, we describe how to infer the 3D poses and arrangement of objects from a 2D generated image by finding a consistent projection of objects onto the 2D scene. We evaluate the quality of Lay-A-Scene using 3D objects from Objaverse and human raters and find that it often generates coherent and feasible 3D object arrangements.
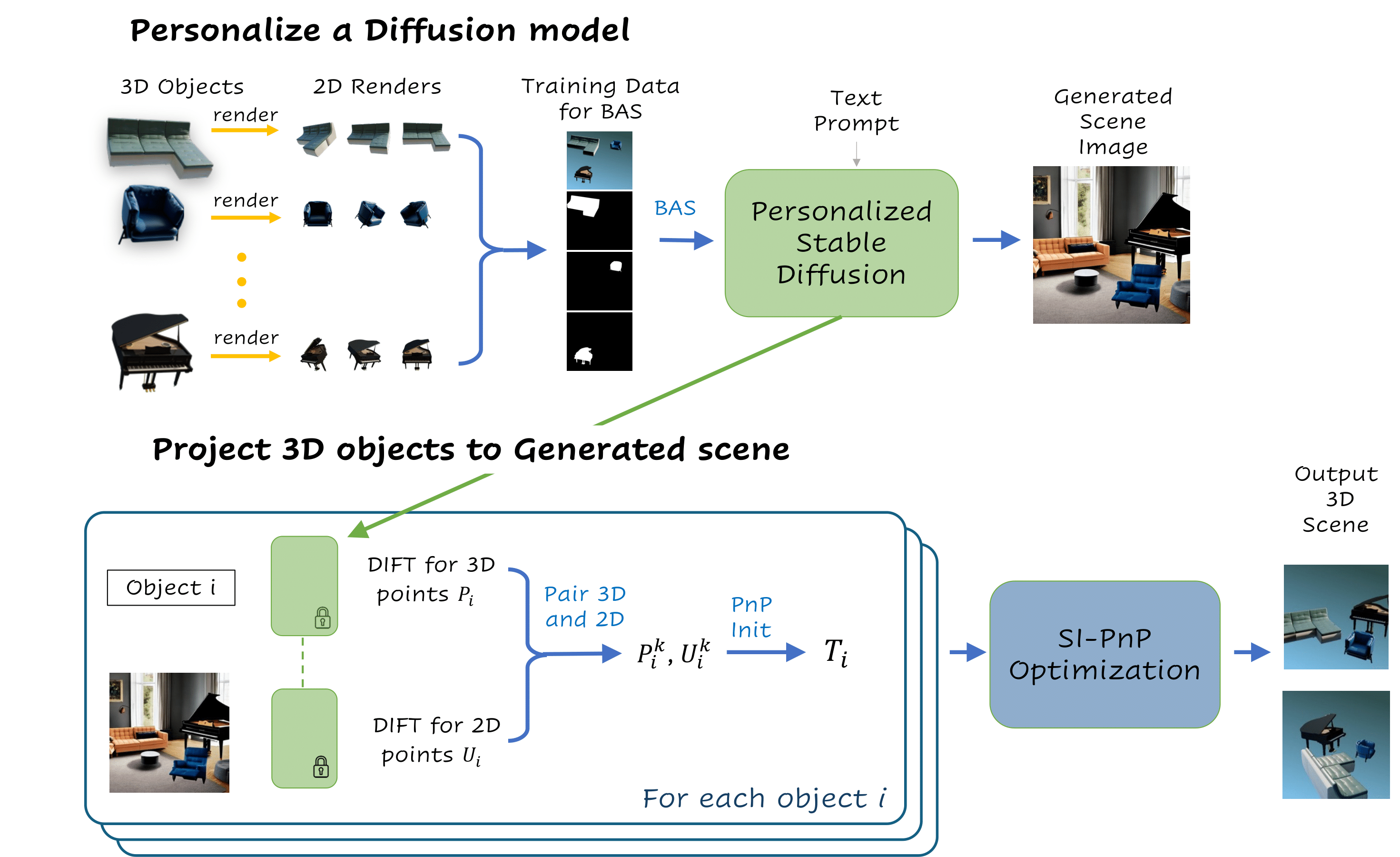
Lay-A-Scene consists of two phases. First, given objects are used to personalize a text-to-image model and a scene image is generated. In the second phase, we find a transformation $T_i$ for each 3D object $i$ to match the 2D arrangement presented in the generated scene image. $T_i$ is found using our \ourpnp{}, by matching the DIFT representation of objects and scene image.
















Example arranged in two columns, where each column has the following structure: Left: a scene image generated by the text-to-image model with these objects. Right: the completed scene. For more examples, please refer to the paper.
@article{rahamim2024lay,
title={Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors},
author={Rahamim, Ohad and Segev, Hilit and Achituve, Idan and Atzmon, Yuval and Kasten, Yoni and Chechik, Gal},
journal={arXiv preprint arXiv:2406.00687},
year={2024}
}
@article{rahamim2024lay,
title={Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors},
author={Rahamim, Ohad and Segev, Hilit and Achituve, Idan and Atzmon, Yuval and Kasten, Yoni and Chechik, Gal},
journal={arXiv preprint arXiv:2406.00687},
year={2024}
}


